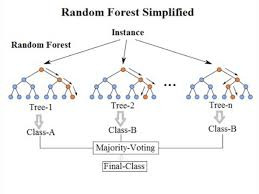
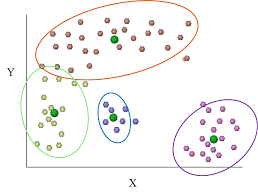
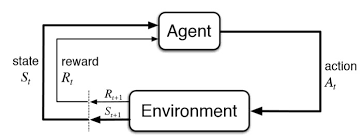
En entradas anteriores hemos comentado qué es y para que sirven las aproximaciones machine Learing y, en esta entrada, me gustaría introducir los algoritmos más importantes de Machine Learning que se están utilizando en la actualidad.
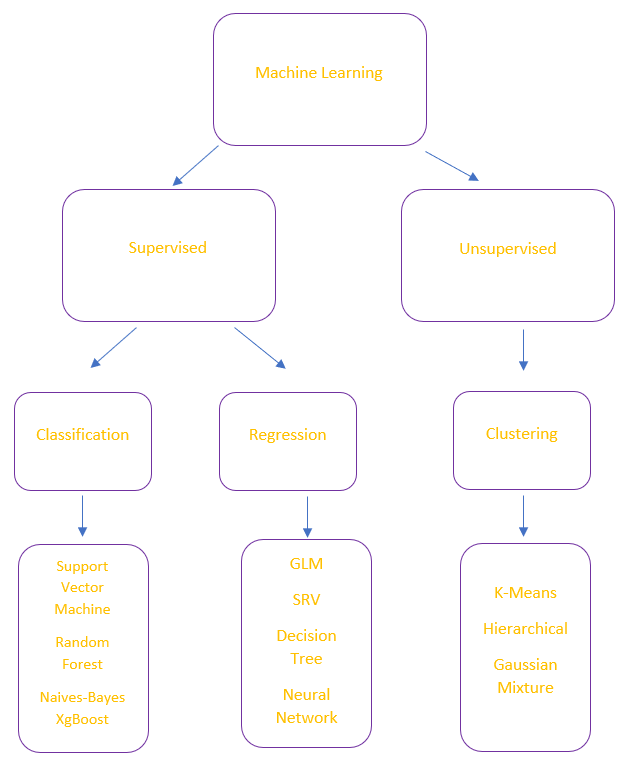
La estrategia que debemos optar para elegir el algoritmo adecuado se represente en el siguiente diagrama de decisión. Debemos realizar dos pregunto para navegar hacía el algoritmo idóneo.
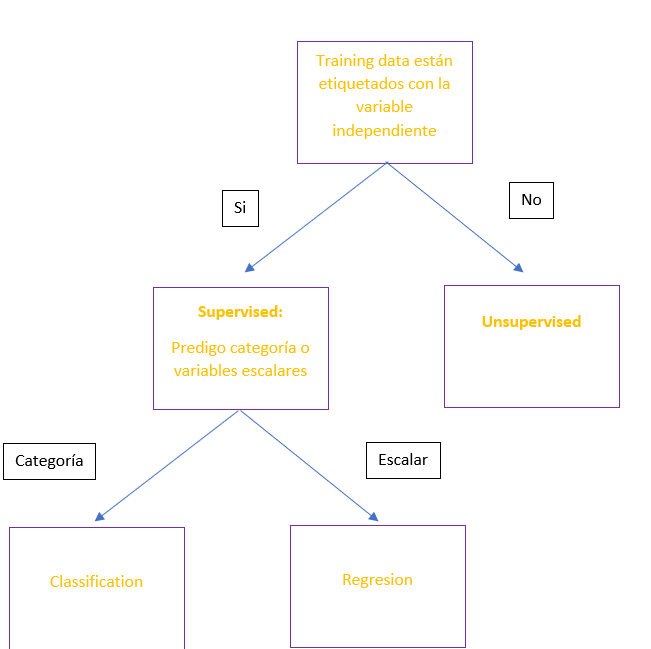
La primera pregunta que nos debemos formular es, qué datos de entrenamiento tengo. Si por ejemplo tengo un conjunto de datos para los que conozco la variable objetivo, por ejemplo, en Real State queremos predecir el precio de un piso en base a sus propias características, y conozco el precio de los pisos para los datos de entrenamiento. En este caso el problema sería supervisado y debería buscar una técnica del lado izquierdo.
La segunda pregunta es ¿Qué quiero predecir? ¿Una variable categórica o una métrica o escalar? Si queremos predecir una variable numérica (Precio, número, porcentajes, etc). Debemos acometer el problema usando regresores para poder predecir el resultado con nuevo dato de prueba en la validación. Si en el caso contrario debemos optar por los datos categóricos debemos usar los algoritmos de classification cuyo output en la predicción sería una variable discreta y categórica.
Una vez definida la estrategia, se procedería a la preparación del dato. Una tarea crucial en los problemas de Machine Learnig. La manipulación de número, codificación de variables categóricas en texto y la normalización son aspectos que deben ser abordados para poder extraer valor de los algoritmos que se esté acometiendo. Esta parte la trataremos en el siguiente Post del blog.