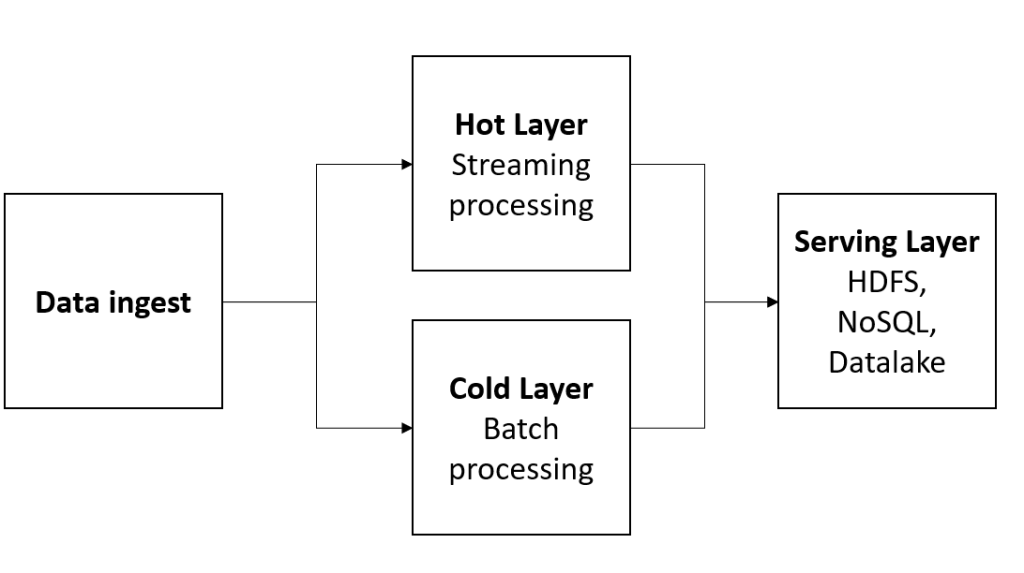
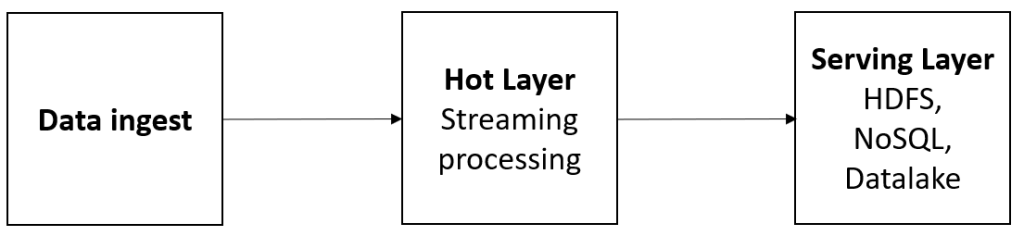
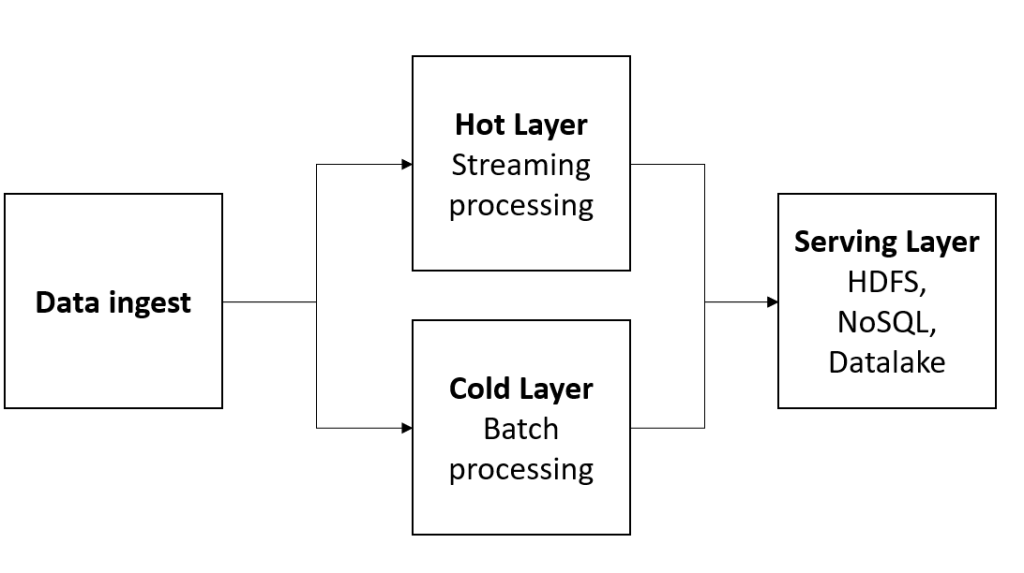
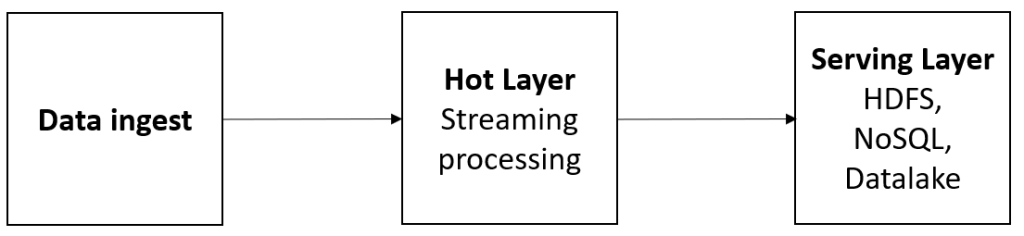
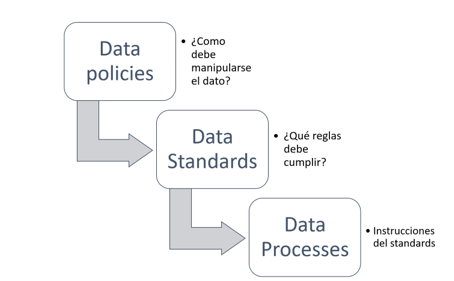
Los principales ingredientes que deben conducir a las organizaciones en la aceptación del modelo de gobierno se muestran a continuación:
Liderazgo y sponsorización de la iniciativa.
- IT debe liderar o en organizaciones en el que el área de data analytics tome protagonismo individual como entidad propia deben liderar la interlocución del proceso de gobierno de datos. Normalmente las organizaciones poseen un área de Business Intelligence que puede aportar los criterios de calidad de dato necesario en el modelo de gobierno. Una tarea debe ser convocar a los busniness owner, mantener el diccionario, glosario de negocio y preservar los KPI’s visibles para que los responsables de datos puedan constatar la validez o la significación del dato que están consumiendo.
- Enfocarse en los datos críticos. No todos los datos de la compañía son igual de importantes. Por ese motivo, es necesario exponerlos en el diccionario y priorizar su impacto en negocio en el foco en poder establecer criterios de calidad muy elevados ya que son un activo fundamental en el proceso de negocio en el que se encuentran.
- Debemos ser capaces de rentabilizar el proyecto a través de los artefactos que hemos generado, el linaje, diccionario, reglas de calidad de negocio, deben imponerse en los proyectos de datos de la empresa y, por tanto, debemos enfatizar su uso e implementar política que se acuerda en el comité de gobierno del dato de la compañía.
- Medir los objetivos KPI’s y el grado de cumplimiento de la compañía. Una de las responsabilidades de los nuevos roles con responsabilidad en el programa de gobierno de datos, debe tener como objetivo que los valores de calidad y el cumplimiento de las políticas sea efectivamente prolífero y por tanto deben definirse dashboards que permita motorizar la monitorización de los objetivos individuales.
- Desde la implementación a través de los planes de remediación debemos celebrar los pequeños quick wins traducidos en una mejora de la calidad, una mayor transparencia de la información, mejor flujo y control del dato gracias a la figura del responsable de mantener los datos, así como un proceso de mejora continua de uno de los activos más valiosos de la compañía.
En este proceso la figura del CDO es vital. Sus tareas para la compañía son:
- Liderar el programa de gobierno del dato
- Operacionalizar los procesos, políticas y estándar definidos por el equipo de gobierno
- Comunicar a los Stakehoders
- Alinear a los data owners en la definición de reglas de negocio
- Impulsar las iniciativas de mejora de calidad
- Definir el diccionario y el glosario de negocio
- Facilitar y apoyar el proyecto MDM
- Establecer herramientas de gobierno
- Auditar y comunicar los KPi’ de objetivo individual de los data owner.
La tarea más importante y probablemente la más difícil consiste en convencer de las ventajas del empoderamiendo de los datos a los stakeholders. Es importante que existe un control riguroso sobre la estructura, el mantenimiento, los valores atípicos para que la decisión de negocio sustentada en el dato pueda ser lo más efectiva posible. Una vez que estos representantes de negocios establezcan las directrices de los propios datos, es posible establecer las políticas, reglas de negocio y calidad que permitan garantizar la mejor explotación de la información posible.
Es importante considerar en qué punto se encuentra mi organización. ¿Hay una política de gobierno de datos activa ¿no? Esta será el estado completamente inmaduro, donde la calidad del dato es desconocida, no existe un programa de mantenimiento de la información, en definitiva, la peor situación. En muchas organizaciones no existe gobierno, pero tal vez sí alguna iniciativa que mejore la calidad. En cualquier caso, los planes de remediación son reactivos por lo que en la mayoría de los casos las inconsistencias de los datos se alargan en el tiempo. El primer estado de madurez interesante posee una cierta organización que acomete problemas de calidad del dato y ha definido roles y responsabilidad por lo que se pueden identificar las persona que velarán por la garantía de calidad del dato. El ultimo nivel sería un sistema pensando en la mejora continua de la calidad, tanto en la detección prematura de los problemas, como en la organización optimizada para minimizar el tiempo de fallo e incluso, poder prevenirlos de manera transparente al proceso de negocio que se esté evaluando. El esquema de los estados se muestra en la figura
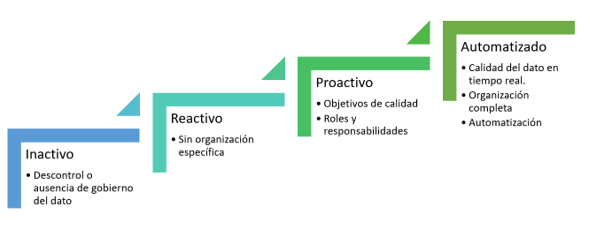
Estado de madurez del gobierno del dato
Es importante considerar en qué punto se encuentra mi organización. ¿Hay una política de gobierno de datos activa ¿no? Esta será el estado completamente inmaduro, donde la calidad del dato es desconocida, no existe un programa de mantenimiento de la información, en definitiva, la peor situación. En muchas organizaciones no existe gobierno, pero tal vez sí alguna iniciativa que mejore la calidad. En cualquier caso, los planes de remediación son reactivos por lo que en la mayoría de los casos las inconsistencias de los datos se alargan en el tiempo. El primer estado de madurez interesante posee una cierta organización que acomete problemas de calidad del dato y ha definido roles y responsabilidad por lo que se pueden identificar las persona que velarán por la garantía de calidad del dato. El ultimo nivel sería un sistema pensando en la mejora continua de la calidad, tanto en la detección prematura de los problemas, como en la organización optimizada para minimizar el tiempo de fallo e incluso, poder prevenirlos de manera transparente al proceso de negocio que se esté evaluando. El esquema de los estados se muestra en la figura
Ilustración 5 Estado de madurez del gobierno del dato
Los beneficios esperados de un proceso de negocio son:
- Identificar de manera rápida dónde están los datos más relevantes.
- Aumentar la confianza y garantizar la veracidad de los datos.
- Proporcionar una visión unificada de los datos a nivel corporativo.
- Detectar proactivamente los problemas de calidad datos.
- Promover un sistema de mejora continua de la calidad de dato.
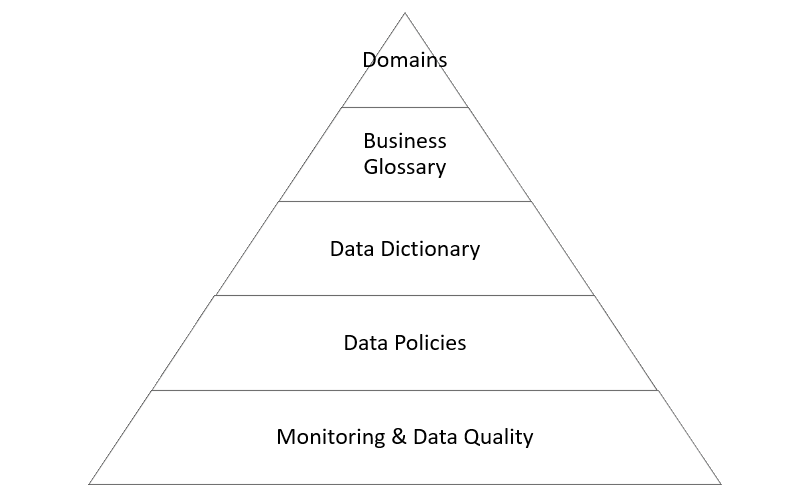
Dentro de los modelos de negocios más relevantes, surgen una serie de nuevos conceptos que debemos dominar si estamos implementando alguna iniciativa de este tipo como puede verse en la figura 1:
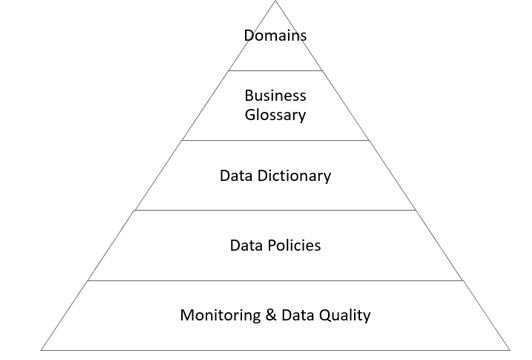
Elementos de una iniciativa de Data Governance
- Business taxonomy. Definir los roles dentro de las organizaciones.
- Business domains. Definición de dominios de información.
- Business Glossary: Definición de los conceptos claves de negocio dentro de cada uno de los dominios.
- Data dictionary: Creación de diccionario de datos, significado de ellos, relación con los términos de negocio e importancia de negocio.
- Data Policies: Definición de las políticas, estándares y reglas de validación de dato.
- KPI’s & monitoring: Establecimiento de KPI’s y sistemas que permitan evaluar las políticas/estándares de calidad del dato
Las organizaciones deben asumir que un proyecto de Gobierno de Datos requiere de roles y responsabilidades dentro de cada uno de los departamentos de la compañía. Es, por tanto, labor de los comités de dirección decidir cómo deben proveer de recursos necesarios para afrontar todas las necesidades del proyecto:
- Data Governance Leader: Creador de estrategia de gobierno de datos y encargado de su implementación y la coordinación del equipo
- Data Owner: Responsable de un dominio de información
- Data Stewards: Responsable de mejorar y mantener la calidad de dato de los elementos definidos en el diccionario.
- Data Producer: Responsables de crear y capturar datos
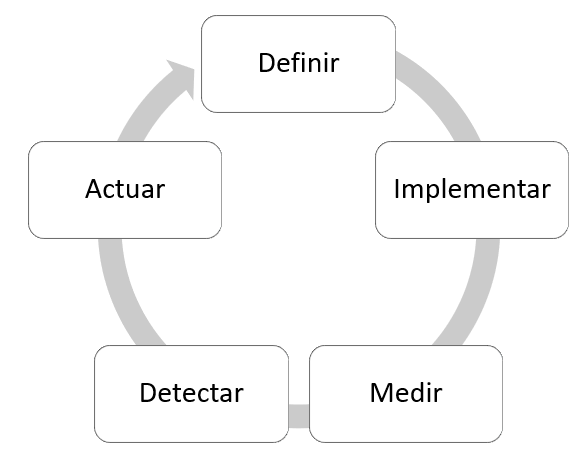
Un buen procedimiento de trabajo, conducido a través de gestión y metodologías de proyecto Agile puede simplificar y potenciar el delivery de soluciones de este tipo en un proceso de mejora
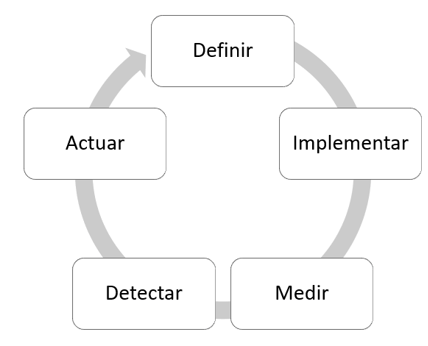
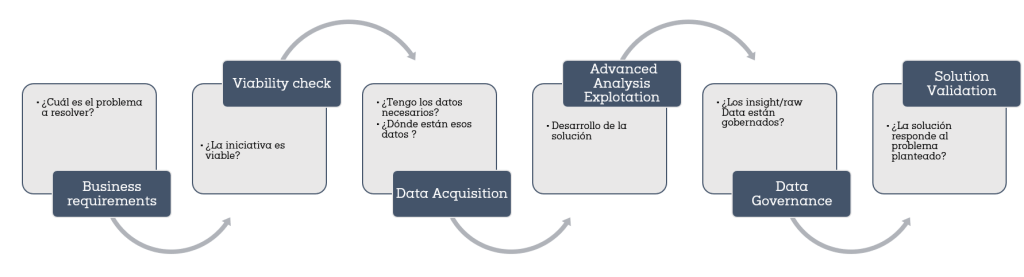
Flujo de ciclo de vida de gobierno del dato