
Como ya es sabido, las tecnologías de datos convencionales no pueden abordar muchas de las problemáticas que se dan en la actualidad. El problema del volumen en ciertas ocasiones es caro y lento en ciertas bases de datos relacionales, los eventos en Streaming debido a la ausencia de velocidad de lectura y procesamiento, la variedad, los datos desestructurados tanto de redes sociales como de Iot devices, la veracidad si son datos confiables o no, y por supuesto el gran valor del dato.
Probablemente deberíamos remontarnos al año 2004 donde se sientan las bases de lo que hoy conocemos como Big Data [1].

A partir de los datos originales es importante saber cómo queremos mapear la tabla que contiene la información. Normalmente se hace un hash sobre un campo usado frecuentemente en las consultas de dicha información. En ese momento se crean sistema clave valor, genera cada uno de los resultados en el nodo que son agrupados en la fase de reduce. Este simple concepto posee numerosas características y es utilizado en los frameworks como hadoop.
En este sentido las gigantes tecnológicas han establecido debido a su problemática a la hora de operar con grandes volúmenes de datos, soluciones tecnológicas y arquitecturas que permiten la manipulación de ingentes cantidades de información. En este campo destacan dos aproximaciones la arquitectura Kappa y Lambda.
Se trata de un patrón de diseño de software y que emplea diferentes sistemas de almacenamientos como bases de datos relacionales y NoSQL y se caracteriza por procesar toda la información en tiempo real y toda la información se trata del mismo modo. Es decir, únicamente existe un flujo de datos por lo que el dato no se bifurca lo que conlleva una mayor coherencia del dato. Este hecho representa una ventaja frente a la arquitectura lambda. Esta arquitectura de muestra en la siguiente figura.
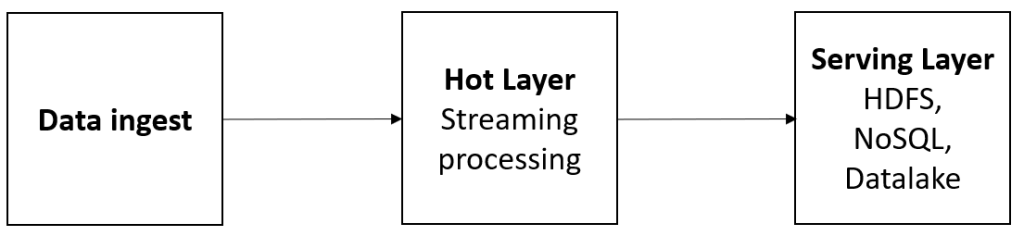
Por un lado, la ingesta del dato ya sea en “streaming” o no, es procesada a través del “hot layer” y el motor de gestión de información de “streaming”. Toda la información relevante, se almacenaría en sistemas de bases de datos NoSQL o bien en los datalakes.
- Sólo hay que reprocesar cuando cambia el código
- Kappa architecture can be used to develop data systems that are online learners and
- Puede ser desplegado con memoria fija
- Escalable horizontalmente
Contras
- Limitaciones para realizar machine learning cuando el tiempo de entrenamiento es elevado.
- La ausencia de “batch” obliga a incorporar un sistema de reproceso o reconciliación de datos
Este tipo de aproximaciones ha sido empleado por empresas como Linkedin
ii. Arquitectura Lambda.
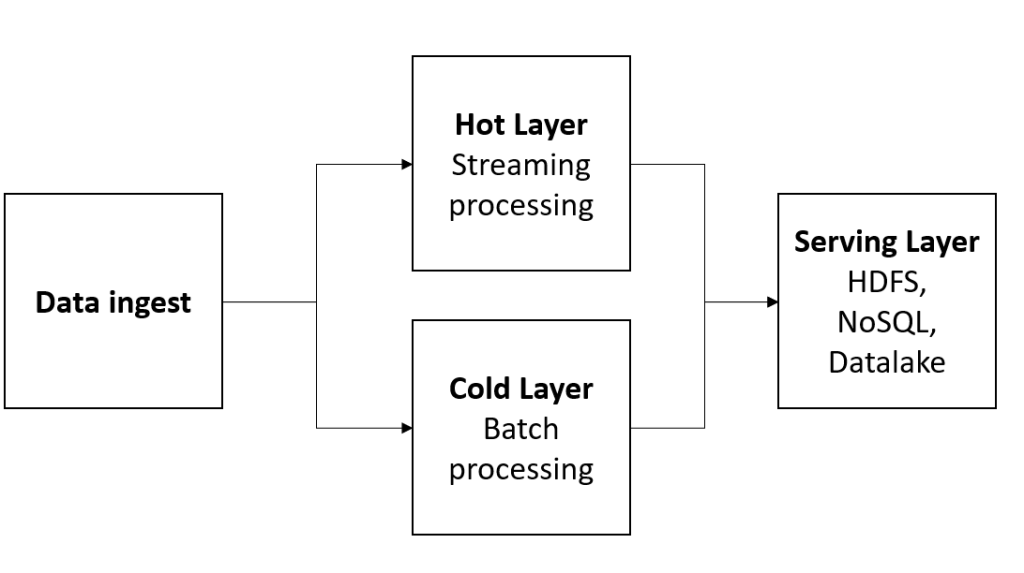
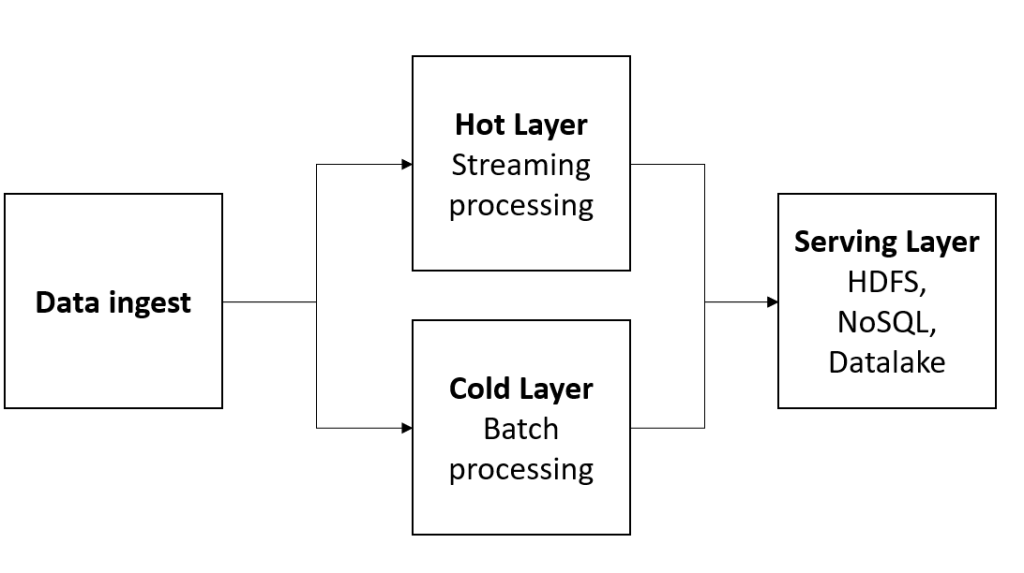
En este tipo de arquitecturas aparecen dos flujos diferentes, la denominada “hot layer”, que procesa la información de “streaming” en tiempo real y la “cold layer”, que procesa la información en forma de lotes o batch.
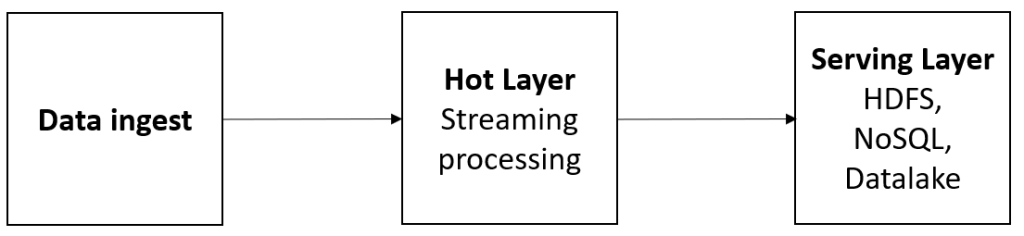
Ilustración 17 Arquitectura Lambda
En este sentido en cada flujo se realizan un tipo de tareas. Por este motivo, es una arquitectura, sin bien más compleja, también es más completa pudiendo abordar cualquier problema analítico. En ciertas tareas como entrenamientos de modelo de machine learning, este tipo de arquitecturas pueden combinar de manera sencilla un algoritmo entrenado con dato en “streaming” para poder consumir tener modelos de inteligencia artificial en tiempo real. También puede realizar macroprocesamiento de dato histórico para combinarlo con el dato del “hot layer” en tiempo real.
Pros
- Es posible tratar gran volumen de información histórica y el tolerante a fallos
- Gran rendimiento y versatilidad
- Totalmente escalable
Contras
- El modelo es complejo de migrar o reorganizar
- El reproceso de información puede no ser beneficioso
