
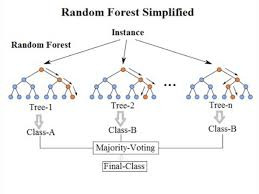
El principal propósito de los mecanismos de Machine Learning es proporcionar una función que, tras enterarse con unos datos reales, pueda producir una predicción a través de las características de un data set, con el intentar predecir la variable dependiente.

Muchos procesos científicos necesitan postular teoría que proporcionen soluciones analíticas que, una vez validadas, generan soluciones completas con funciones empíricas que permiten inducir unas variables a partir de los otros datos. Sin embargo, las técnicas de Machine Learning no usan esta aproximación. Esta función no es relevante para resolver el problema. Machine Learning sólo entiende de inputs (variables usadas como predictores) y de output (variable dependiente), y no le interesa conocer la función que los relaciona sino aprender patrones de comportamiento que permitan establecer un output en función de unos determinados inputs.
Existen dos aproximaciones diferentes:
- Supervisado: El problema tiene un determinado conjunto de datos de entrenamiento y el problema objetivo está definido en una determina variable. P.e. precio de la vivienda. Nuestro conjunto de datos tiene información sobre el precio de los pisos en Madrid el último año (metros cuadrados, precio, piso, clasificación energética, zona, etc…) y el valor del precio, variable que nos interesa predecir. Nuestro modelo pretende relacionar el precio de un determinado inmueble con el valor de este. El entrenamiento puede validar dicha función contra el precio, detectar tendencia y patrones, y cuando termine el entrenamiento, predecir el precio del piso. El resultado del aprendizaje y predicción será un valor.
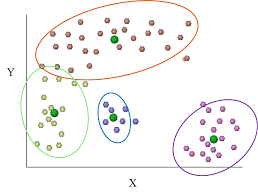
- No supervisado: En el caso del aprendizaje no supervisado no tenemos ninguna variable objetivo con el que comparar. Simplemente tenemos un conjunto de inputs per no conocemos el output. Una de la técnica más relevante es el clustering. Tenemos muchos datos y queremos ver si existe algunas características que permita agrupar sus atributos y crear una etiqueta con valores comunes de las características. Imaginemos que queremos comprar un automóvil de unas características. Y tenemos muchos atributos que definen al registro en cuestión, tamaño, potencia, rango de precio, tipo de motor, marca. Un análisis de tipo clustering definiría diferentes conjuntos de datos debido a la similitud entre los registros que se están analizando y, crear grupos de registros con características similares.
- No supervisado: Consiste en un proceso iterativo que permite a un agente aprender en base a su propia experiencia. De manera similar a Machine Learning supervisado, esto procesos tratan de relación los inputs o características con las variables dependientes, ya sean categóricas con variables escalares.
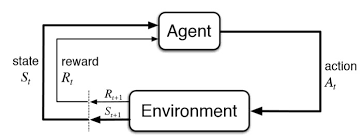
El proceso sería el siguiente, en cada una de las interacciones el agente prueba una determinada acción en el entorno y, de ese modo, optimiza el accuracy* del modelo para producir el mejor algoritmo en base a los datos de entrenamiento.
